목차
iBOT: Image BERT Pre-Training with Online Tokenizer
ICLR 2022
https://arxiv.org/abs/2111.07832
iBOT: Image BERT Pre-Training with Online Tokenizer
The success of language Transformers is primarily attributed to the pretext task of masked language modeling (MLM), where texts are first tokenized into semantically meaningful pieces. In this work, we study masked image modeling (MIM) and indicate the adv
arxiv.org


언어 트랜스포머의 성공은 주로 텍스트를 의미론적으로 의미 있는 조각으로 처음 토큰화하는 masked language modeling (MLM) (Devlin et al., 2019)의 pretext 작업에 기인합니다.
본 연구에서는 masked language modeling (MIM)을 연구하고 의미론적으로 의미 있는 visual tokenizer를 사용하는 것의 장점과 과제를 나타냅니다.
이 논문에서는 online tokenizer로 마스킹된 예측을 수행할 수 있는 self-supervised 프레임워크 iBOT를 제시합니다.
특히 마스크된 패치 토큰에 대해 self-distillation을 수행하고 teacher 네트워크를 online tokenizer로 사용하여 시각적 의미를 획득합니다.
online tokenizer는 MIM objective와 공동으로 학습할 수 있으며 tokenizer를 사전 교육해야 하는 multi-stage training pipeline과 함께 제공됩니다.
ImageNet-1K에서 평가된 82.3%의 in-ear probing accuracy와 87.8%의 fine-tuning accuracy를 달성하였습니다.
1. Introduction

NLP에서 Masked Language Modeling (MLM)은 입력 토큰 세트를 무작위로 마스킹한 후 재구성하는 언어 모델의 인기 있는 pre-training 패러다임입니다.
이 연구는 MLM의 성공을 이어나가고 NLP에서와 같이 표준 구성 요소 역할을 할 수 있도록 더 나은 비전 트랜스포머를 훈련하기 위한 Masked Image Modeling (MIM)을 탐색합니다.
이를 위해 Online Tokenizer로 MIM을 수행하는 새로운 프레임워크인 iBOT (image BERT pre-training with Online Tokenizer)을 제시합니다.
knowledge distillation (KD)로 MIM을 공식화하여 iBOT를 동기 부여하고, online tokenizer로 twin teacher의 도움을 받아 MIM에 대한 self-distillation을 수행할 것을 제안합니다.
대상 네트워크에는 마스크된 이미지가 공급되고, online tokenizer에는 원래 이미지가 공급됩니다.
목표는 대상 네트워크가 각 마스크된 패치 토큰을 해당 tokenizer 출력으로 복구할 수 있도록 하는 것입니다.
online tokenizer는 두 가지 주요 과제를 자연스럽게 해결합니다.
- tokenizer는 클래스 토큰에 cross-view 이미지의 유사성을 적용하여 점진적으로 학습된 high-level 시각적 의미를 캡처합니다.
- tokenizer는 모멘텀 업데이트를 통해 MIM과 공동으로 최적화되므로 pre-processing으로 추가 단계의 교육이 필요하지 않습니다.
2. Preliminaries
iBOT과 가장 가까운 연구는 BERT에서의 MLM과 유사하게 이미지에 적용한 BEiT의 MIM, 그리고 label 없이 self-distillation을 사용하여 self-supervised learning을 한 DINO입니다.
2.1. Masked image modeling as knowledge distillation
https://arxiv.org/abs/2106.08254
BEiT: BERT Pre-Training of Image Transformers
We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pre
arxiv.org

BEiT는 BERT에서의 MLM를 이미지에 적용한 MIM을 소개했습니다.
BEiT는 먼저 원래 이미지를 시각적 토큰으로 "토큰화"합니다.
그런 다음 일부 이미지 패치를 무작위로 마스킹하여 백본 트랜스포머에 공급합니다.
손상된 이미지 패치를 기반으로 원래의 시각적 토큰을 복구하는 방법으로 pre-training합니다.
2.2. Self-Distillation

DINO는 self-distillation을 통해 pre-training하였습니다.
같은 구조를 가지는 teacher 네트워크와 student 네트워크를 구성하여, teacher 네트워크에는 global view만 전달하고 student 네트워크에는 모든 crop을 전달하여 “local-to-global” 대응이 권장됩니다.
Knowledge distillation 방식과 다르게, 여기에서는 미리 주어진 teacher가 없기 때문에 student 네트워크의 과거 반복으로부터 teacher를 구축합니다.
student 가중치에 exponential moving average (EMA), 즉 momentum encoder를 사용하여 teacher에 전달합니다.
https://sundong.tistory.com/12
[논문 리뷰] Emerging Properties in Self-Supervised Vision Transformers (ICCV 2021)
목차 Emerging Properties in Self-Supervised Vision Transformers ICCV 2021 https://arxiv.org/abs/2104.14294 Emerging Properties in Self-Supervised Vision Transformers In this paper, we question if self-supervised learning provides new properties to Vision
sundong.tistory.com
3. iBOT

iBOT에서는 token-generation self-supervised objective로 self-distillation를 제시하고 self-distillation을 통한 MIM을 수행합니다.
3.1. Framework

우선 입력 이미지 $x$를 서로 다르게 augmentation하여 $u$와 $v$를 얻습니다.
그리고 $u$와 $v$에 blockwise masking을 하여 $\hat{u}$와 $\hat{v}$을 얻습니다.
masking된 $\hat{u}$와 $\hat{v}$는 student의 입력으로 사용되고 $u$와 $v$는 teacher의 입력으로 사용됩니다.
patch tokens의 projections에서 MIM의 loss는 다음과 같이 정의합니다:
$$L_{MIM}=-\sum_{i=1}^{N}m_i \cdot P_{\theta'}^{patch}(u_i)^T \log P_{\theta}^{patch}(\hat{u}_i).$$
$v$에서도 마찬가지로 진행하여 둘의 평균으로 loss를 구합니다.
iBOT에 사용되는 tokenizer 는 추가 단계에서 pre-training을 받을 필요 없이 MIM 목표에 대해 공동으로 학습할 수 있으며, 도메인 지식을 지정된 데이터 세트에 고정하는 대신 현재 데이터 세트에서 distillate할 수 있습니다.
online tokenizer가 의미론적으로 의미가 있음을 보장하기 위해, 대부분의 self-supervised 방법(He et al., 2020; Grill et al., 2020; Caron et al., 2021)이 달성한 대로 bootstrapping을 통해 시각적 의미론을 얻을 수 있도록 cross-view 이미지의 [CLS] 토큰에 대해 self-distillation를 수행합니다.
의미론이 거의 확실한 토큰화된 단어와 달리 이미지 패치는 의미론적 의미가 모호합니다.
따라서 one-hot discretization로서의 토큰화는 이미지에 대해 차선책이 될 수 있습니다.
iBOT에서는 one-hot 토큰 id 대신 softmax 이후의 토큰 분포를 감독 신호로 사용하는데, 이는 iBOT 사전 훈련에서 중요한 역할을 합니다.
3.2. Implementation
Architecture
Vision Transformers (Dosovitskiy et al., 2021), Swin Transformers (Liu et al., 2021b)의 ViT-S/16, ViT-B/16, ViT-L/16, Swin-T/{7,14}를 백본으로 사용하였습니다.
224 사이즈의 이미지로 트랜스포머를 사전 교육하고 미세 조정하기 때문에 패치 토큰의 개수는 총 196개입니다.
projection head h는 DINO를 따라 l2-normalized bottleneck을 가진 3-layer MLPs입니다.
4. Experiment
4.1. Classification on ImageNet-1K
k-NN and Linear Probing

DINO를 따라 k-NN과 Linear classifier를 사용하여 평가하였을 때 state-of-the-art를 달성했습니다.
Fine-Tuning
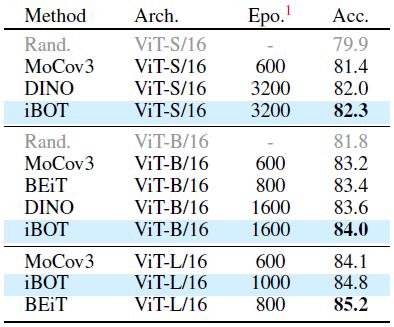

Fine-tuning에서도 좋은 성능을 보여줍니다.
ViT-L/16에서는 iBOT는 1K 데이터를 사용하는 BEiT보다 0.4% 나쁘지만, 22K 데이터를 사용하면 0.6% 더 좋습니다.
이는 더 큰 모델을 훈련하기 위해 iBOT가 더 많은 데이터를 필요로 한다는 것을 의미합니다.
Semi-Supervised and Unsupervised Learning

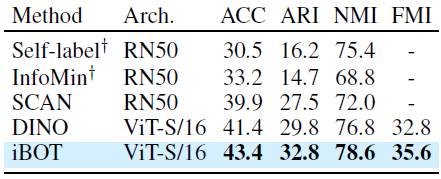
Semi-supervised and Unsupervised Learning에서도 state of the art를 달성하였습니다.
4.2. Downstream tasks
Object Detection and Instance Segmentation on COCO & Semantic Segmentation on ADE20K

Transfer Learning

다양한 downstream tasks에도 잘 적용됩니다.
4.3. Properties of ViT trained with MIM
논문에서는 iBOT의 속성을 추가로 분석하였습니다.
What Patterns Does MIM Learn?

self-distillation에 사용되는 Projection Head의 출력은 패치 토큰에 대해 확률적 분포를 나타냅니다.
MIM이 학습하도록 유도하는 패턴을 이해하기 위해 여러 패턴 레이아웃을 시각화하였니다.
위의 그림에서 보는 바와 같이, 여러 패치는 명확한 의미론으로 그룹화되어 있습니다.
How Does MIM Help Image Recognition?

더 나은 부분 의미론의 속성이 이미지 인식에 어떻게 도움이 될 수 있는지 설명하기 위해 부분별 선형 분류를 사용하여 패치 토큰과 [CLS] 토큰의 표현 사이의 관계를 연구합니다.
구체적으로, 상위 k개의 self-attention 점수를 가진 패치 토큰을 평균합니다.
그 결과는 위의 그림에 나타나 있습니다.
패치 표현을 직접 사용할 때 iBOT가 DINO를 능가한다는 것을 관찰합니다.
상위 56개의 패치 토큰을 사용하면 최적의 결과를 얻을 수 있고, iBOT가 디노보다 5.9% 높다는 것을 관찰하였습니다.
성능 격차는 패치 토큰을 더 적게 사용할 때 더 두드러집니다.
self-attention 점수가 가장 높은 패치 토큰만 사용할 경우 iBOT는 17.9% 발전합니다.
이러한 결과는 패치 토큰에 대한 iBOT 표현에서 의미 정보를 많이 드러내며, 이는 모델이 로컬 세부 정보 손실에 더 강력하고 이미지 수준 인식에 대한 성능을 더욱 향상시키는 데 도움이 된다는 것을 말합니다.
Discriminative parts in self-attention map

분석을 위해 ViT-S/16으로 self-attention map을 시각화합니다.
쿼리로 [CLS] 토큰을 선택하고 그림과 같이 다른 색상으로 마지막 레이어의 다른 헤드에서 attention map을 시각화합니다.
iBOT은 다른 개체 또는 하나의 개체의 다른 부분을 분리하는 견고한 능력을 보여줍니다.
iBOT는 주로 개체의 구별되는 부분(예: 자동차 바퀴, 새 부리)에 초점을 맞춥니다.
Robustness

MIM은 일반적이지 않은 예제에 대한 모델의 견고성을 향상시킬 수 있습니다.
배경 변화, occlusion 및 out-of-distribution의 세 가지 측면에서 견고성을 정량적으로 벤치마킹하였을 때, 견고성을 보여줍니다.
4.4. Ablation study on tokenizer

iBOT은 BEiT와 DINO를 합친 방법입니다.
self-supervised pre-training 방법으로 많이 사용되고 있으며 다양한 downstream task에서도 잘 작동합니다.
최근 iBOT을 개선한 DINOv2도 발표되었는데, 조만간 다뤄보도록 하겠습니다.

https://dinov2.metademolab.com
DINOv2 by Meta AI
A self-supervised vision transformer model by Meta AI
dinov2.metademolab.com
Code
https://github.com/bytedance/ibot
GitHub - bytedance/ibot: iBOT :robot:: Image BERT Pre-Training with Online Tokenizer (ICLR 2022)
iBOT :robot:: Image BERT Pre-Training with Online Tokenizer (ICLR 2022) - GitHub - bytedance/ibot: iBOT :robot:: Image BERT Pre-Training with Online Tokenizer (ICLR 2022)
github.com
'논문 읽기 > Self-Supervised Learning' 카테고리의 다른 글
| [논문 리뷰] Emerging Properties in Self-Supervised Vision Transformers (ICCV 2021) (2) | 2023.09.14 |
|---|