목차
Image Segmentation Using Deep Learning: A Survey
https://ieeexplore.ieee.org/abstract/document/9356353
Image Segmentation Using Deep Learning: A Survey
Image segmentation is a key task in computer vision and image processing with important applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among others, and nu
ieeexplore.ieee.org
이번에는 image segmentation에서의 데이터셋들을 간단히 정리해 보도록 하겠습니다.
1. 2D Datasets
1) PASCAL Visual Object Classes
http://host.robots.ox.ac.uk/pascal/VOC/
The PASCAL Visual Object Classes Homepage
2006 10 classes: bicycle, bus, car, cat, cow, dog, horse, motorbike, person, sheep. Train/validation/test: 2618 images containing 4754 annotated objects. Images from flickr and from Microsoft Research Cambridge (MSRC) dataset The MSRC images were easier th
host.robots.ox.ac.uk
https://link.springer.com/article/10.1007/s11263-009-0275-4
https://link.springer.com/article/10.1007/s11263-014-0733-5

PASCAL Visual Object Classes (VOC)는 컴퓨터 비전에서 가장 인기 있는 데이터 세트 중 하나로 classification, segmentation, detection, action recognition, person layout의 5가지 작업에 주석이 달린 이미지를 사용할 수 있습니다.
segmentation 작업은 21개 클래스의 객체 레이블이 있습니다.
차량, 가정, 동물, 항공기, 자전거, 보트, 버스, 자동차, 오토바이, 기차, 병, 의자, 식탁, 화분, 소파, TV/모니터, 새, 고양이, 소, 개, 말, 양 및 사람(픽셀은 이러한 클래스에 속하지 않으면 배경 레이블로 지정됨).
이 데이터셋은 훈련 및 검증의 두 가지 세트로 나뉘며 각각 1,464개와 1,449개의 이미지가 있습니다.
그리고 실제 과제에 대한 비공개 테스트 세트가 있습니다.
2) Microsoft Common Objects in Context
COCO - Common Objects in Context
cocodataset.org
https://arxiv.org/abs/1405.0312
Microsoft COCO: Common Objects in Context
We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding. This is achieved by gathering images of complex ever
arxiv.org

Microsoft Common Objects in Context (MS COCO)는 또 다른 대규모 객체 탐지, 분할 및 캡션 데이터셋입니다.
COCO에는 복잡한 일상 장면의 이미지가 포함되어 있으며, 자연적인 맥락에 공통 객체가 포함되어 있습니다.
이 데이터 세트에는 91개 객체 유형의 사진이 포함되어 있으며, 328k 이미지에는 총 250만 개의 레이블이 지정된 인스턴스가 있습니다.
그림 34는 MS-COCO 레이블과 주어진 샘플 이미지에 대한 이전 데이터 세트의 차이를 보여줍니다. 탐지 과제에는 80개 이상의 클래스가 포함되어 있으며, 훈련용 82k 이미지, 검증용 40.5k 이미지, 테스트 세트용 80k 이미지 이상을 제공합니다.
3) Cityscapes
https://www.cityscapes-dataset.com/
Cityscapes Dataset – Semantic Understanding of Urban Street Scenes
The Cityscapes Dataset We present a new large-scale dataset that contains a diverse set of stereo video sequences recorded in street scenes from 50 different cities, with high quality pixel-level annotations of 5 000 frames in addition to a larger set o
www.cityscapes-dataset.com
https://arxiv.org/abs/1604.01685
The Cityscapes Dataset for Semantic Urban Scene Understanding
Visual understanding of complex urban street scenes is an enabling factor for a wide range of applications. Object detection has benefited enormously from large-scale datasets, especially in the context of deep learning. For semantic urban scene understand
arxiv.org

Cityscapes은 도시의 거리 장면에 대한 의미론적 이해에 중점을 둔 대규모 데이터베이스입니다.
50개 도시의 거리 장면에 기록된 다양한 스테레오 비디오 시퀀스 세트가 포함되어 있으며, 5k 프레임의 고품질 픽셀 수준 주석과 함께 20k 약한 주석이 달린 프레임 세트가 포함되어 있습니다.
평면, 인간, 차량, 건설, 객체, 자연, 하늘 및 공허의 8가지 범주로 그룹화된 30개 클래스의 의미론적 및 밀도 높은 픽셀 주석이 포함되어 있습니다.
4) ADE20K / MIT Scene Parsing (SceneParse150)
https://groups.csail.mit.edu/vision/datasets/ADE20K/
ADE20K dataset
Database --> Full Dataset Register here to download the ADE20K dataset and annotations. By doing so, you agree to the terms of use. Toolkit See our GitHub Repository for an overview of how to access and explore ADE20K. Scene Parsing Benchmark Scene parsing
groups.csail.mit.edu
https://ieeexplore.ieee.org/document/8100027
Scene Parsing through ADE20K Dataset
Scene parsing, or recognizing and segmenting objects and stuff in an image, is one of the key problems in computer vision. Despite the communitys efforts in data collection, there are still few image datasets covering a wide range of scenes and object cate
ieeexplore.ieee.org

ADE20K / MIT Scene Parsing (SceneParse150)은 장면 파싱 알고리듬에 대한 표준 교육 및 평가 플랫폼을 제공합니다.
이 벤치마크에 대한 데이터는 객체 및 객체 부분으로 주석이 달린 20K 이상의 장면 중심 이미지를 포함하는 ADE20K 데이터 세트[132]에서 가져온 것입니다.
벤치마크는 훈련을 위한 20K 이미지, 검증을 위한 2K 이미지 및 테스트를 위한 다른 이미지 배치로 구분됩니다.
이 데이터 세트에는 150개의 의미 범주가 있습니다.
5) KITTI
https://www.cvlibs.net/datasets/kitti/
The KITTI Vision Benchmark Suite
We thank Karlsruhe Institute of Technology (KIT) and Toyota Technological Institute at Chicago (TTI-C) for funding this project and Jan Cech (CTU) and Pablo Fernandez Alcantarilla (UoA) for providing initial results. We further thank our 3D object labeling
www.cvlibs.net
https://ieeexplore.ieee.org/document/6248074
Are we ready for autonomous driving? The KITTI vision benchmark suite
Today, visual recognition systems are still rarely employed in robotics applications. Perhaps one of the main reasons for this is the lack of demanding benchmarks that mimic such scenarios. In this paper, we take advantage of our autonomous driving platfor
ieeexplore.ieee.org
KITTI는 모바일 로봇 공학 및 자율 주행을 위한 가장 인기 있는 데이터셋 중 하나입니다.
여기에는 다양한 센서 양식(고해상도 RGB, 그레이스케일 스테레오 카메라 및 3D 레이저 스캐너 포함)으로 기록된 교통 시나리오의 몇 시간 분량의 비디오가 포함되어 있습니다.
원래 데이터셋에는 semantic segmentation를 위한 정보가 포함되어 있지 않지만 연구자들은 연구 목적으로 데이터셋의 일부에 수동으로 주석을 달았습니다.
2. 2.5D Datasets
2.5D Datasets은 RGB-D 이미지를 사용하는 데이터셋입니다.
1) NYU-D V2
https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
NYU Depth V2 « Nathan Silberman
NYU Depth Dataset V2 Nathan Silberman, Pushmeet Kohli, Derek Hoiem, Rob Fergus If you use the dataset, please cite the following work: Indoor Segmentation and Support Inference from RGBD Images ECCV 2012 [PDF][Bib] Samples of the RGB image, the raw depth i
cs.nyu.edu
https://link.springer.com/chapter/10.1007/978-3-642-33715-4_54

NYU-D V2는 마이크로소프트 키넥트의 RGB와 깊이 카메라에 의해 녹화된 다양한 실내 장면의 비디오 시퀀스로 구성되어 있습니다.
정렬된 RGB와 3개 도시에서 찍은 450개 이상의 장면의 깊이 이미지의 1,449쌍의 조밀하게 레이블이 지정되어 있습니다.
각 개체에는 클래스와 인스턴스 번호(예: 컵 1, 컵 2, 컵 3 등)로 레이블이 지정되어 있습니다.
또한 레이블이 지정되지 않은 407,024개의 프레임이 포함되어 있습니다.
이 데이터셋은 기존의 다른 데이터셋에 비해 상대적으로 작습니다.
3. 3D Datasets
3D 데이터셋은 로봇, 의료 영상 분석, 3D 장면 분석 및 구축 등에서 중요하게 사용됩니다.
3차원 영상은 보통 메쉬 또는 포인트 클라우드와 같은 볼륨 표현을 통해 제공됩니다.
1) Stanford 2D-3D-Semantics Dataset (2D-3D-S)
http://buildingparser.stanford.edu/dataset.html
Large Scale Parsing
Fig 2. Data Processing. The RGB output of the scanner is registered on the 3D modalities (each yellow marker represents one scan). We then process the RGB and 3D data to make depth, surface normals, and 2D semantic (projected from 3D semantics) images for
buildingparser.stanford.edu
https://arxiv.org/abs/1702.01105
Joint 2D-3D-Semantic Data for Indoor Scene Understanding
We present a dataset of large-scale indoor spaces that provides a variety of mutually registered modalities from 2D, 2.5D and 3D domains, with instance-level semantic and geometric annotations. The dataset covers over 6,000m2 and contains over 70,000 RGB i
arxiv.org

Stanford 2D-3D-Semantics Dataset (2D-3D-S)는 인스턴스 수준의 주석과 함께 2D, 2.5D 및 3D 도메인의 다양한 데이터를 제공하며 6개의 실내 영역에서 수집됩니다.
70,000개 이상의 RGB 이미지와 해당 깊이, 표면 정규, 의미 주석, 글로벌 XYZ 이미지 및 카메라 정보를 포함합니다.
2) ShapeNetCore
ShapeNet
ShapeNet is an ongoing effort to establish a richly-annotated, large-scale dataset of 3D shapes. We provide researchers around the world with this data to enable research in computer graphics, computer vision, robotics, and other related disciplines. Shape
shapenet.org
https://arxiv.org/abs/1512.03012
ShapeNet: An Information-Rich 3D Model Repository
We present ShapeNet: a richly-annotated, large-scale repository of shapes represented by 3D CAD models of objects. ShapeNet contains 3D models from a multitude of semantic categories and organizes them under the WordNet taxonomy. It is a collection of data
arxiv.org

ShapeNetCore는 깨끗한 단일 3D 모델과 수동으로 검증된 카테고리 및 정렬 주석이 있는 전체 ShapeNet 데이터셋의 하위 집합입니다.
이는 55개의 일반적인 객체 카테고리와 약 51,300개의 고유한 3D 모델을 포함합니다.
3) Sydney Urban Objects Dataset
https://www.acfr.usyd.edu.au/papers/SydneyUrbanObjectsDataset.shtml
Sydney Urban Objects Dataset - ACFR - The University of Sydney
--> Sydney Urban Objects Dataset (formerly objects4) Collected by Alastair Quadros, James Underwood, Bertrand Douillard; 2013 This dataset contains a variety of common urban road objects scanned with a Velodyne HDL-64E LIDAR, collected in the CBD of Sydney
www.acfr.usyd.edu.au
https://www.araa.asn.au/acra/acra2013/papers/pap133s1-file1.pdf

Sydney Urban Objects Dataset은 호주 시드니의 중심 업무 지구에서 Velodyne HDL-64E 라이다로 스캔된 다양한 일반적인 도시 도로 객체가 포함되어 있습니다.차량, 보행자, 표지판 및 나무 클래스에 걸쳐 631개의 객체에 대한 개별 스캔이 있습니다.
4) nuScenes
https://www.nuscenes.org/
www.nuscenes.org
https://arxiv.org/abs/1903.11027
nuScenes: A multimodal dataset for autonomous driving
Robust detection and tracking of objects is crucial for the deployment of autonomous vehicle technology. Image based benchmark datasets have driven development in computer vision tasks such as object detection, tracking and segmentation of agents in the en
arxiv.org
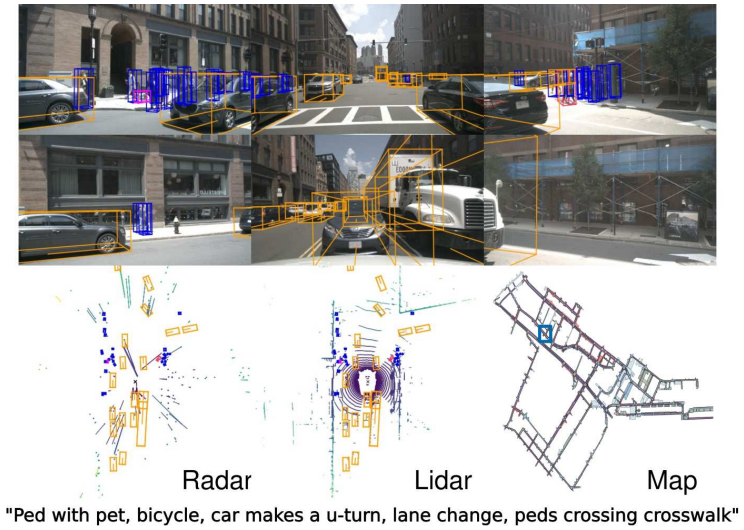
nuScenes은 전체 360도 시야를 모두 갖춘 6대의 카메라, 5대의 레이더 및 1대의 라이다로 구성된 전체 자율 주행 차량 센서 제품군을 운반하는 데이터셋입니다.
nuScenes은 각 장면의 길이가 20대이며 23개의 클래스와 8개의 특성에 대한 3D 경계 상자로 완전히 주석이 달린 1000개의 장면으로 구성됩니다.
이는 KITTI 데이터셋보다 7배 많은 주석과 100배의 이미지를 가지고 있습니다.
5) SemanticKITTI
http://www.semantic-kitti.org/
SemanticKITTI - A Dataset for LiDAR-based Semantic Scene Understanding
Dynamic We annotated moving and non-moving traffic participants with distinct classes, including cars, trucks, motorcycles, pedestrians, and bicyclists. This enables to reason about dynamic objects in the scene.
www.semantic-kitti.org
https://arxiv.org/abs/1904.01416
SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences
Semantic scene understanding is important for various applications. In particular, self-driving cars need a fine-grained understanding of the surfaces and objects in their vicinity. Light detection and ranging (LiDAR) provides precise geometric information
arxiv.org

SemanticKITTI는 레이저 기반 의미 분할에 대한 연구를 추진하기 위해 대규모 데이터셋입니다.
KITTI 비전 오도메트리 벤치마크의 모든 시퀀스에 주석을 달았고, 자동차 LiDAR의 전체 360º 시야에 대한 조밀한 지점 단위 주석을 제공합니다.
이 데이터셋은
(i) semantic segmentation of point clouds using a single scan
(ii) semantic segmentation using multiple past scans
(iii) semantic scene completion
의 세 가지 벤치마크 작업을 제안합니다.
6) KITTI-360
https://www.cvlibs.net/datasets/kitti-360
KITTI-360
About We present a large-scale dataset that contains rich sensory information and full annotations. We recorded several suburbs of Karlsruhe, Germany, corresponding to over 320k images and 100k laser scans in a driving distance of 73.7km. We annotate both
www.cvlibs.net
https://arxiv.org/abs/2109.13410
KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D
For the last few decades, several major subfields of artificial intelligence including computer vision, graphics, and robotics have progressed largely independently from each other. Recently, however, the community has realized that progress towards robust
arxiv.org

KITTI-360은 비전, 그래픽 및 로보틱스의 교차점에서 연구를 용이하게 하기 위해 더 풍부한 입력 modalities, 포괄적인 semantic instance 주석 및 정확한 localization 구성된 교외 주행 데이터 세트입니다.
2D와 3D에 걸쳐 일관된 semantic instance 주석으로 150k 이상의 이미지와 1B의 3D 포인트를 생성했습니다.