SACuP: Sonar Image Augmentation with Cut and Paste Based DataBank for Semantic Segmentation
Remote Sensing 15 (21), 5185
https://www.mdpi.com/2072-4292/15/21/5185
SACuP: Sonar Image Augmentation with Cut and Paste Based DataBank for Semantic Segmentation
In this paper, we introduce Sonar image Augmentation with Cut and Paste based DataBank for semantic segmentation (SACuP), a novel data augmentation framework specifically designed for sonar imagery. Unlike traditional methods that often overlook the distin
www.mdpi.com
이번 글에서는 제 첫 논문인 SACuP 연구를 소개해보려 합니다.
연구의 시작은 2022년 1학기(3학년 2학기)에 수강했던 미래자동차·로봇캡스톤디자인 수업이었습니다.
한 학기 이상 길게 진행되는 장기 프로젝트였던 만큼, 평소 관심 가졌던 분야들을 마음껏 해 보고 싶은 욕심이 컸습니다.
당시 제게는 두 가지 큰 관심사가 있었습니다.
첫 번째는 제 본 전공인 생체의공학을 살려 생체 신호(EEG, ECG, EMG, PPG 등)를 해석하고 이를 로봇 제어에 응용하는 것이었고, 두 번째는 개인적으로 관심이 있었던 미지의 영역, 즉 제약이 많고 위험한 수중 환경을 탐사하는 수중 로봇 분야였습니다.
결과적으로는 수중 로봇을 최종 주제로 선택했습니다.
생체 신호를 해석하여 로봇을 제어하는 것보다, SONAR를 이용한 수중 물체 탐지가 기한 내에 더 명확하고 정량화된 결과를 얻을 수 있을 것이라 판단했기 때문입니다.
처음에는 무인잠수정(UUV)의 소나를 이용해 물체를 탐지하고 제어까지 하는 거대한 프로젝트를 꿈꿨습니다.
하지만 연구를 진행하며 배경 조사를 거듭할수록 소나 데이터의 문제가 명확하게 보였습니다.
그래서 모두 다 하려는 것보다, '소나 데이터에 특화된 증강(augmentation) 기법을 통한 분할(segmentation) 성능 향상'이라는 더 구체적이고 정량적인 문제를 정의하게 되었습니다.
결국 소나 데이터에 특화된 증강(augmentation) 기법을 성공적으로 개발했고, SACuP이라는 첫 논문을 출판하게 되었습니다.
이 논문에서는 수중음향의 특성보다는 이미지 관점에서 소나 이미지 맞춤형 증강 기법을 제안하였습니다.
1. Introduction
무인 수중 탐사 분야에서 딥러닝을 활용한 객체 인식 및 세그먼테이션(semantic segmentation)의 중요성은 점점 커지고 있습니다.
하지만 수중 환경은 빛의 흡수와 산란 때문에 지상에서처럼 일반 카메라를 사용하기가 매우 어렵습니다.
따라서 수중 환경의 센싱은 주로 음파를 이용하는 소나(SONAR) 센서에 의존하게 됩니다.
하지만 소나 이미지는 일반 광학 카메라 이미지와 본질적으로 다른 특성을 가집니다.
- 높은 노이즈와 낮은 해상도
- 카메라와 다른 음파 기반 생성 원리와 이에 따른 그림자(shadow) 발생
가장 큰 문제는 "데이터 부족"입니다.
수중 환경에서 소나 데이터를 수집하는 것은 장비와 인력의 한계로 인해 비용이 매우 많이 들고 복잡합니다.
딥러닝 모델의 과적합(Overfitting)을 막고 일반화 성능을 높이려면 양질의 대규모 데이터셋이 필수적인데, 충분한 데이터를 얻기 어려운 현실입니다.
2. 기존 데이터 증강(Data Augmentation) 방식의 문제점
딥러닝에서 데이터가 부족할 때 흔히 쓰는 방법이 바로 데이터 증강(Data Augmentation)입니다.
하지만 기존 이미지 비전 분야에서 잘 작동하던 방식(CutOut, CutMix, 단순 회전 및 반전 등)을 소나 이미지에 그대로 적용하면 문제가 발생합니다.
| 기존 기법 | 소나 이미지 적용 시 문제점 |
| 전통적 증강 (회전, 반전 등) | 소나 이미지의 고유한 기하학적 특성을 무너뜨리며, 특히 그림자의 방향성에 문제를 일으킴. |
| CutOut / CutMix | 노이즈나 그림자 같은 소나의 특성을 반영하지 못해 데이터를 적절히 활용하지 못함. |
| ObjectAug | 객체 단위 증강이라는 아이디어는 좋으나 소나 고유의 특성(그림자 등)을 여전히 반영하지 못함. |
즉, 소나의 특성(노이즈, 그림자)을 유지하면서, 실제처럼 자연스러운 데이터를 만들어낼 수 있는 소나 전용 증강 기법이 필요합니다.
3. SACuP의 핵심 아이디어 및 파이프라인
SACuP(Sonar image Augmentation with Cut and Paste based DataBank for semantic segmentation)은 추가적인 수동 작업 없이 기존 데이터(이미지와 마스크)만을 활용하여 데이터를 증강합니다.
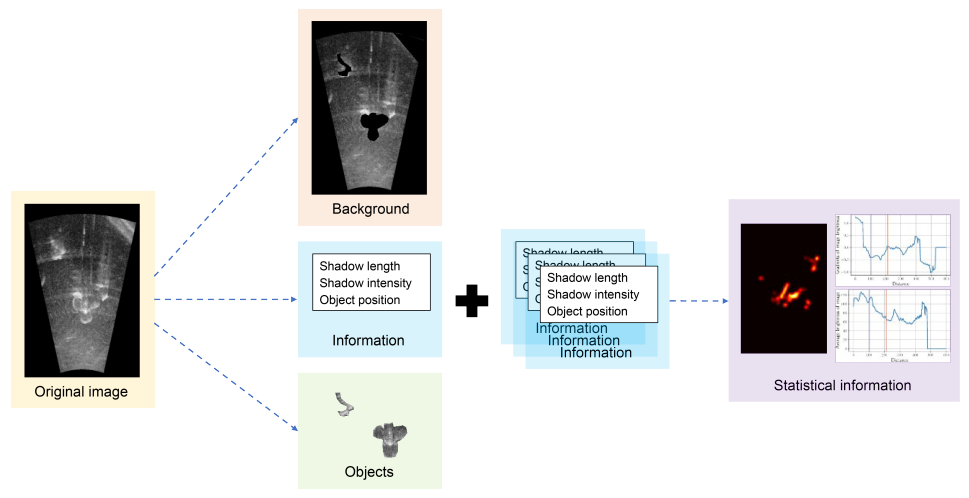
핵심은 DataBank라는 공간에 배경, 객체, 그리고 위치 및 그림자 같은 통계적 정보를 따로 추출해 저장하고, 이를 현실감 있게 조합하여 새로운 이미지를 생성하는 것입니다.
파이프라인은 크게 4단계로 구성됩니다.
① DataBank Generation (데이터뱅크 생성)
원본 이미지와 정답(Ground Truth) 마스크를 이용해 배경(Background)과 객체(Object)를 분리하여 추출합니다.
이때 객체만 딱 맞게 자르는 것이 아니라 팽창(Dilation) 연산을 통해 주변 배경을 살짝 포함시켜 추출합니다.
여기서 가장 중요한 포인트는 각 클래스별 그림자 길이, 그림자 강도, 소나 노이즈의 표준 편차, 그리고 객체의 위치 분포(Heatmap) 등의 통계 정보(Statistical Information)를 함께 추출하여 DataBank에 저장한다는 것입니다.
② Background Inpainting (배경 복원)
객체를 떼어내고 나면 원래 있던 배경에 구멍(Hole)이 생깁니다.
이 구멍을 자연스럽게 메우기 위해 pix2pix를 사용했습니다.
정답(Ground Truth) 배경 데이터가 따로 없다는 문제를 해결하기 위해, 원래 마스크와 겹치지 않는 새로운 가상의 마스크를 임의로 생성하여 모델이 '객체가 빠진 빈 공간에 알맞은 배경을 스스로 생성하는 법'을 학습하도록 새로운 전략을 짰습니다.

③ Object Insertion (객체 삽입 및 밝기 보정)
DataBank에서 객체를 무작위로 선택한 후, 통계 정보의 객체의 위치 분포에 따라 객체를 배치합니다 (이때 다른 객체와 겹치는지 검사합니다).
여기서 특히 신경 쓴 부분은 밝기 보정(Adjusting Brightness)입니다.
객체를 떼어올 때 같이 가져온 '주변 배경'의 평균 밝기와, 객체가 새로 삽입될 '타겟 배경'의 평균 밝기 차이(difference)를 계산하여 객체의 밝기를 동적으로 조정합니다.
이후 가우시안 필터를 이용해 알파 블렌딩(Alpha-blending)을 수행하여 객체가 배경에 이질감 없이 자연스럽게 만들었습니다.

④ Shadow Generation (그림자 생성)
음파가 닿지 않는 객체 뒤편에는 필연적으로 맹점인 어두운 그림자가 생기는데, 새로 합성한 객체에는 그림자가 없으므로 이를 인공적으로 생성해야 합니다.
- 소나의 위치(시야가 수렴하는 하단 중앙점)를 가정하고, 그 반대 방향으로 그림자가 뻗어 나가게 만듭니다.
- 객체의 높이가 길면 그림자도 길게 형성되는 물리적 특성을 DataBank의 그림자 통계 정보를 통해 반영했습니다.
- 소나 노이즈의 특성을 파괴하지 않기 위해 단순히 그림자 영역을 까맣게 지우는 것이 아니라, 그림자 강도를 평균으로 하고 노이즈의 표준편차를 적용한 가우시안 노이즈(Gaussian Noise)로 채워 넣어 진짜 소나 이미지처럼 그림자를 생성했습니다.

아래는 SACuP의 전체 파이프라인입니다.

4. 실험
4.1. Dataset
연구의 메인 데이터셋으로는 전방 주시 소나(FLS: Forward Looking Sonar)를 통해 수집된 해양 쓰레기(Marine Debris) 데이터를 사용했습니다.
- 데이터 수집 환경 및 센서 스펙: 이 데이터는 가로 3m, 세로 12m, 깊이 4m의 인공 수조(Water tank) 환경에서 ARIS Explorer 3000 센서를 사용하여 수집되었습니다. 소나의 주파수는 3.0 MHz로 설정되었으며, 128개의 빔(Beam)을 통해 30° × 15°의 시야각(FoV)을 가집니다. 수중 바닥의 객체를 탐지하기 위해 피치 각도(Pitch angle)는 15°에서 30° 사이로 세팅되었습니다.
- 데이터 구성: 480 × 320 해상도의 그레이스케일(Grayscale) 이미지로 구성되며, 배경(Background)을 포함하여 총 12개의 클래스(Bottle, Can, Chain, Hook, Propeller, Tire, Valve, Wall 등)로 픽셀 단위 분류가 되어 있습니다. 모호한 마스크를 제외하고 최종적으로 1,755장의 데이터를 사용했습니다.
- 데이터셋의 한계점 (클래스 불균형): 딥러닝 학습을 진행하기에 1,755장의 데이터는 절대적인 양이 부족합니다. 나아가 데이터셋 내부를 분석해 본 결과, 극심한 클래스 불균형(Class Imbalance) 문제가 존재했습니다. 벽(Wall)이나 타이어(Tire) 클래스는 객체와 픽셀 수가 압도적으로 많은 반면, 샴푸통(Shampoo-bottle)이나 서 있는 병(Standing-bottle) 같은 작은 객체들은 데이터가 절대적으로 부족했습니다.
4.2. 실험 결과
제안한 파이프라인의 성능 검증은 세그먼테이션의 대표적인 모델인 U-Net(ResNet-18 인코더)을 통해 이루어졌습니다.
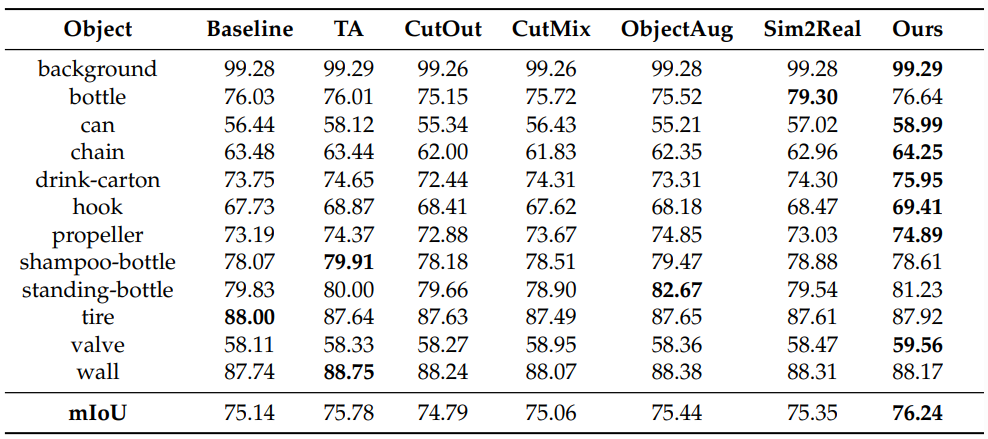
- mIoU 성능 향상: 증강을 전혀 거치지 않은 베이스라인(Baseline)의 mIoU가 75.14%였던 반면, SACuP을 적용했을 때는 76.24%로 약 1.10%의 성능 향상을 기록했습니다.
- 기존 증강 기법들과의 성능 비교: Traditional Augmentation(75.78%), CutOut(74.79%), CutMix(75.06%), ObjectAug(75.44%), 그리고 3D 시뮬레이터를 활용해 가상 데이터를 생성하는 Sim2Real(75.35%) 등 널리 쓰이는 다른 증강 기법들과 비교했을 때도 SACuP이 가장 높은 성능을 보여주었습니다.
- 정성적 평가 (클래스별 세부분석): 세그먼테이션 결과 이미지를 확인해 보면 성과가 더욱 뚜렷합니다. 캔(Can), 우유곽(drink-carton) 같이 픽셀 수가 적은 작은 객체나 훅(Hook), 체인(Chain), 프로펠러(Propeller)처럼 형태와 경계가 모호한 객체들의 경우, SACuP 모델이 다른 방식들보다 훨씬 더 정확하게 영역을 분할해 내는 것을 확인할 수 있었습니다.

4.3. Ablation Study
안한 각 단계(Cut & Paste, 밝기 보정, 그림자 생성)가 모델 학습에 독립적으로 유의미한 영향을 미쳤는지 확인하기 위해 Ablation Study(절제 연구)를 진행했습니다.
- 단순 Cut & Paste 기법만 적용: 75.79% (+0.65% 향상)
- 밝기 보정(Adjust Brightness) 모듈 추가: 75.85% (+0.71% 향상)
- 그림자 생성(Shadow Generation) 모듈 추가: 75.90% (+0.76% 향상)
- 모든 기법을 종합한 SACuP (Ours): 76.24% (+1.10% 최고 성능 달성)

이 결과는 소나 환경의 물리적 특성을 유지하기 위해 고안한 밝기 보정과 인공적인 그림자 생성 과정이 실제 모델의 학습 및 일반화 능력을 극대화하는 데 핵심적인 역할을 했음을 증명합니다.
4.4. 다양한 딥러닝 모델 검증
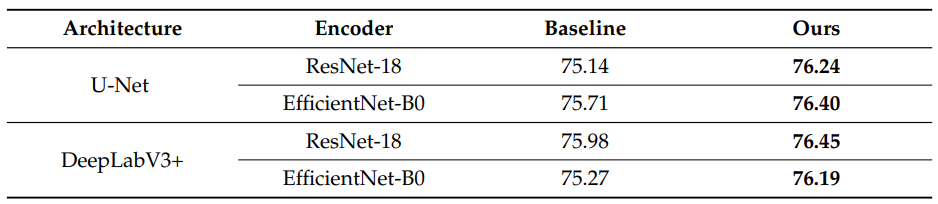
제안한 데이터 증강 파이프라인이 특정 신경망 구조에만 맞춰진 기법이 아님을 검증하기 위해, 시맨틱 세그먼테이션(Semantic Segmentation) 분야에서 널리 사용되는 다양한 아키텍처와 인코더(Encoder) 조합을 대상으로 확장 실험을 진행했습니다.
실험은 간결한 인코더-디코더 구조의 U-Net과, Atrous Convolution을 활용해 멀티스케일(Multi-scale) 특징을 잘 잡아내는 DeepLabV3+ 두 가지 구조를 채택했습니다.
또한, 각 모델의 백본(Backbone) 네트워크로는 ResNet-18과 EfficientNet-B0를 적용했습니다.
[실험 결과: 아키텍처별 mIoU 성능 변화]
- U-Net
- ResNet-18: 75.14% ➔ 76.24% (+1.10% 향상)
- EfficientNet-B0: 75.71% ➔ 76.40% (+0.69% 향상)
- DeepLabV3+
- ResNet-18: 75.98% ➔ 76.45% (+0.47% 향상)
- EfficientNet-B0: 75.27% ➔ 76.19% (+0.92% 향상)
실험 결과, 모델의 구조(U-Net, DeepLabV3+)나 특징 추출을 담당하는 인코더(ResNet, EfficientNet)의 종류와 무관하게 모든 조합에서 일관된 mIoU 성능 향상이 확인되었습니다.
이러한 결과는 SACuP이 단순히 특정 딥러닝 아키텍처의 특성에 의존하여 성능을 올리는 것이 아니라, 소나 이미지의 본질적인 특성(그림자, 밝기 등)을 데이터 차원에서 근본적으로 개선했음을 보여줍니다.
4.5. 다양한 데이터셋 검증
마지막으로, 제안한 기법이 특정 환경이나 모델, 특정 소나 센서(ARIS 3000)에만 종속되는 모델이 아님을 검증했습니다.
이를 위해 Teledyne BlueView M900-90 (주파수 900 kHz, 90° × 20° FoV) 소나를 이용해 실제 저수지와 수조(가로 10m, 세로 12m, 깊이 1.5m) 환경에서 수집된 USI (Underwater Sonar Image) 데이터셋에 SACuP 기법을 적용했습니다.
해당 데이터셋은 배경과 객체, 두 개의 클래스만 갖습니다.
- 베이스라인(Baseline): 79.59%
- SACuP 적용 후 (Ours): 84.19% (4.60% 상승)
이 실험을 통해 SACuP 파이프라인이 수집 환경이나 센서의 주파수 및 스펙이 달라지더라도, 뛰어난 강건성(Robustness)과 일반화(Generalization) 성능을 보장한다는 것을 최종적으로 입증했습니다.


이 글을 쓰고 있는 2026년 현재, SACuP이 출판된 지도 3년이라는 시간이 흘렀습니다.
지금 되돌아보면 아쉬운 점들도 많습니다.
가장 크게 남는 아쉬움은 '수중음향학(Underwater Acoustics)'에 대한 근본적인 고려가 부족했다는 점입니다.
SACuP은 철저히 컴퓨터 비전(Computer Vision)과 이미지 프로세싱의 관점에서 소나 데이터를 다루었습니다.
하지만 실제 소나의 그림자와 노이즈는 단순히 시각적인 픽셀의 변화가 아니라, 매질의 밀도, 수중 음속, 반사 등 복잡한 음향학적 물리 법칙의 결과물입니다.
이를 수학적/물리적으로 모델링하지 못하고, 통계적인 시각 정보로만 근사하여 증강했다는 점은 이 연구의 뚜렷한 한계점입니다.
딥러닝과 비전 AI 기술이 하루가 다르게 발전하는 만큼, 많은 것이 달라졌습니다.
그만큼 확장의 여지도 몇 가지 보입니다.
- 수중음향학(Acoustics) 기반의 데이터 증강: 단순한 픽셀 조작을 넘어, 음파의 전달 방정식을 딥러닝 파이프라인에 통합(Physics-informed)하여 훨씬 더 물리적으로 타당한 그림자와 노이즈를 생성하는 연구로 고도화할 수 있습니다.
- ViT(Vision Transformer) 구조로의 확장: 당시에는 U-Net과 DeepLabV3+ 등 CNN 기반 아키텍처에 국한하여 검증했지만, 현재 대세로 자리 잡은 ViT나 후속 어텐션(Attention) 기반 모델들에 SACuP을 적용했을 때에도 작동하는지 실험해 볼 여지가 많습니다.
- 새로운 소나 데이터셋의 도입: 더 복잡한 해저 지형과 다양한 객체가 포함된 대규모 공개 데이터셋에 이 증강 기법을 적용해 본다면 더 유의미한 통찰을 얻을 수 있을 것입니다.
첫 논문이었던 만큼 아쉬움도 많지만, 논문 출판의 한 사이클을 겪으면서 문제를 정의하고 해결하고 정리하는 과정을 배울 수 있었던 것 같습니다.
Code
https://github.com/AIRLABkhu/SACuP
GitHub - AIRLABkhu/SACuP
Contribute to AIRLABkhu/SACuP development by creating an account on GitHub.
github.com
'연구 노트 > Vision AI' 카테고리의 다른 글
| [연구 노트] 시뮬레이터를 이용한 SONAR 데이터 증강(Data Augmentation) (0) | 2026.04.26 |
|---|---|
| [연구 노트] DRIM: Depth Restoration with Interference Mitigation in Multiple LiDAR Depth Cameras (0) | 2025.11.24 |