시뮬레이터를 이용한 SONAR 데이터 증강(Data Augmentation)
(2022. 03. ~ 2022. 12.)
이번 글에서는 연구노트라는 카테고리에 맞게, 논문으로 이어지지는 못했지만 진행했었던 프로젝트 얘기를 해보려 합니다.
비록 논문으로 빛을 보지는 못했지만, 학부 프로젝트로 한 학기 이상 진행하면서 여러 가지 아이디어를 냈었고, 이 당시의 고민과 실패 경험이 SACuP이라는 결실을 맺게 했기에 연구 노트로 남겨두고자 합니다.
1. 개요
1.1. 배경 및 필요성
바닷속은 극심한 수압과 빛의 감쇠 현상으로 인해 사람의 접근이 제한적이며, 일반적인 광학 카메라로는 시야를 확보하기 매우 어려운 미지의 영역입니다.
이러한 가혹한 환경적 제약 때문에 인명 구조, 심해 탐사, 해양 쓰레기 탐지와 같은 주요 임무에는 무인잠수정(UUV)과 전방 주시 소나(Forward Looking SONAR, FLS), 그중에서도 다중빔 소나(Multibeam Sonar)가 필수적으로 활용됩니다.
최근 수중 탐사에 AI 기술을 적극적으로 도입하고 있지만, 여기서 치명적인 병목 현상(Bottleneck)이 발생합니다.
비전 AI를 비롯한 모든 딥러닝 모델은 과적합(Overfitting)을 방지하고 뛰어난 탐지 성능을 내기 위해 근본적으로 '방대하고 질 좋은 학습 데이터'를 끝없이 요구한다는 점입니다.
하지만 수중 환경은 복잡하고 변수가 많아, 데이터를 수집하기 위한 무인잠수정과 소나 장비 운용에 막대한 비용이 발생합니다.
결과적으로 AI 모델의 일반화 성능 확보에 필수적인 대규모 데이터를 실제 해양 수집만으로 충당하는 것은 불가능에 가까우며, 이는 수중 딥러닝 연구의 가장 큰 장벽이 되고 있습니다.
이러한 고질적인 데이터 부족 문제와 물리적, 경제적 한계를 극복하기 위한 대안으로 시뮬레이터의 도입을 고려할 수 있습니다.
시뮬레이터 환경에서 가상의 소나 데이터를 무한히 합성하여 AI 모델의 학습 데이터로 보충해 준다면, 천문학적인 데이터 수집 비용을 획기적으로 절감하는 동시에 수중 객체 인식을 위한 의미론적 분할(Semantic Segmentation) AI 모델의 탐지 성능도 효과적으로 향상시킬 수 있을 것으로 기대됩니다.
1.2. 연구 주요내용
본 연구의 핵심은 실제 수중 환경에서 수집된 전방 주시 소나 데이터(Real)와 소나 시뮬레이터에서 생성된 가상 데이터(Sim)를 결합하여, 의미론적 분할(Semantic Segmentation) 모델의 성능 향상을 정량적으로 비교하고 검증하는 것입니다.
특히, 가상 데이터를 생성하는 과정에서 시뮬레이터 내 타겟 객체의 위치와 물리적 상태를 무작위로 변환하고, 이에 매칭되는 픽셀 단위의 정답 마스크(Ground-Truth)를 자동으로 생성하는 데이터 수집 파이프라인을 구축합니다.
이를 통해 수동 라벨링(Annotation)에 소요되는 막대한 비용과 시간을 원천적으로 제거할 수 있습니다.
궁극적으로는 시뮬레이터 기반의 가상 데이터(Sim)와 실제 데이터(Real)를 효과적으로 혼합하여, 수중 객체 탐지 모델의 세그먼테이션 정확도를 향상시키고자 합니다.
2. 데이터셋 및 시뮬레이터 환경
가상 데이터(Sim)의 생성과 그 효과를 검증하기 위해, 기준이 되는 실제 데이터셋과 이를 모사할 시뮬레이터 환경을 구축했습니다.
2.1. 실제 수중 소나 데이터셋
- 타겟 데이터셋: Forward-Looking Sonar Marine Debris Datasets
- 사용 센서: ARIS Explorer 3000 다중빔 전방 주시 소나
- 특징: 해양 쓰레기 탐지를 목적으로 수집됨
2.2. 소나 시뮬레이터 환경
- 플랫폼: Project DAVE 기반 Gazebo 시뮬레이터
- 센서 모사: 타겟 센서인 ARIS Explorer 3000과 물리적으로 유사한 결과물을 얻기 위해 시뮬레이터 내 소나의 주파수와 시야각(FOV)을 조정했습니다.
3. 방법
3.1. 자동화된 가상 데이터 및 마스크 수집 파이프라인
수동 라벨링 비용을 없애기 위해 시뮬레이터 상에서 다음의 과정을 반복하여 학습 데이터 쌍(Image & Mask)을 생성했습니다.
- Gazebo 환경의 해저에 1~5개의 무작위 물체를 생성하고 전체 소나 이미지를 투영합니다.
- 바닥을 제거하고 물체를 하나씩만 남겨 물체의 각각 투영된 이미지를 얻습니다.
- 정답 마스크에 수중 소나 특유의 노이즈를 필터링하기 위해, 물체당 10장의 이미지를 연속 수집해 평균을 내고 특정 임계값(Threshold) 이상을 클래스 ID로 칠해 마스크를 생성합니다.
- 다수의 객체가 존재할 때 겹치거나 음파가 닿지 않아 생기는 그림자(Occlusion) 현상을 반영하기 위해, 전체 투영 이미지와 비교하여 실제 시야에 노출되는 부분만 마스크로 남겼습니다.
3.2. Depth Camera 좌표 변환 기반 모사
Ray 기반 소나 센서 외에도, Gazebo의 Depth Camera가 수집한 Point Cloud 정보를 활용하여 소나 이미지 형태로 좌표를 변환하는 실험을 병행했습니다.
이를 통해 ARIS Explorer 3000의 기하학적 특성에 가까운 대체 데이터를 추출하는 방법론을 고안했습니다.
4. 실험 결과
4.1. 베이스라인 결과
가장 먼저 베이스라인 성능을 확인하기 위해, 실제 수중 데이터셋만을 이용하여 다양한 의미론적 분할(Semantic Segmentation) 모델들의 학습을 진행했습니다.
U-Net을 기반으로 다양한 인코더를 결합하여 도출한 초기 mIoU 결과는 다음과 같습니다.
| Unet | Unet +RN18 |
Unet +RN34 |
Unet +RN50 |
Unet +RN101 |
Unet +RN152 |
Unet +VGG16 |
Unet +VGG19 |
|
| mIoU | 0.7448 | 0.7141 | 0.7291 | 0.7137 | 0.7219 | 0.6879 | 0.7181 | 0.7091 |
4.2. 메인 실험 결과
이후 가상 데이터를 생성하기 위해 Gazebo 시뮬레이터 상에서 타겟 센서인 ARIS Explorer 3000과 유사하도록 FOV와 주파수를 정밀하게 조정했습니다.
바닥에 1~5개의 물체를 생성하고 투영된 소나 이미지를 얻은 뒤, 바닥을 제거하고 각 물체 단위의 이미지를 분리해 내는 과정을 반복하여 노이즈가 제거된 깨끗한 가상 이미지와 정답 마스크(Ground-Truth) 쌍을 성공적으로 수집했습니다.

이렇게 확보한 가상의 소나 이미지를 실제 해양 쓰레기 데이터셋(Marine Debris Datasets)에 각각 0.2배, 0.5배, 1배, 1.8배의 비율로 혼합하여 모델의 성능 변화를 평가했습니다.
그 결과, 시뮬레이터에서 생성한 이미지를 학습에 추가했을 때 기존 베이스라인 성능을 뛰어넘는 유의미한 결과가 다수 관찰되었습니다.
| Real:Sim | Unet | Unet +RN18 |
Unet +RN34 |
Unet +RN50 |
Unet +RN101 |
Unet +RN152 |
Unet +VGG16 |
Unet +VGG19 |
| 1:0.2 | 0.7481 | 0.7230 | 0.7081 | 0.6911 | 0.7183 | 0.7124 | 0.7321 | 0.7142 |
| 1:0.5 | 0.7359 | 0.7298 | 0.7352 | 0.7250 | 0.7163 | 0.7275 | 0.7353 | 0.7319 |
| 1:1 | 0.7429 | 0.7321 | 0.7358 | 0.7241 | 0.7389 | 0.7286 | 0.7381 | 0.7311 |
| 1:1.8 | 0.7453 | 0.7276 | 0.7459 | 0.7320 | 0.7415 | 0.7456 | 0.7300 | 0.7367 |

특히 기본 U-Net 아키텍처에 가상 데이터를 0.2배 혼합했을 때(1:0.2) 최고 mIoU 0.7481을 기록하며 베이스라인(0.7448) 수치를 상회했습니다.
또한 ResNet-34 등 일부 인코더에서는 가상 데이터 비율을 1.8배까지 크게 늘렸을 때 오히려 성능이 극대화되는 경향을 보였습니다.
4.3. 학습 효율성 실험 결과
성능 향상뿐만 아니라 학습 효율성 측면에서도 괄목할 만한 결과를 얻었습니다.
범용적인 ImageNet 기반의 사전 학습(Pre-trained) 모델을 사용하거나 사전 학습 없이 처음부터(From scratch) 학습하는 것보다, 가상의 소나 이미지만으로 사전 학습을 거친 모델이 실제 데이터셋을 학습할 때 훨씬 더 빠르고 안정적으로 수렴하는 것을 확인했습니다.
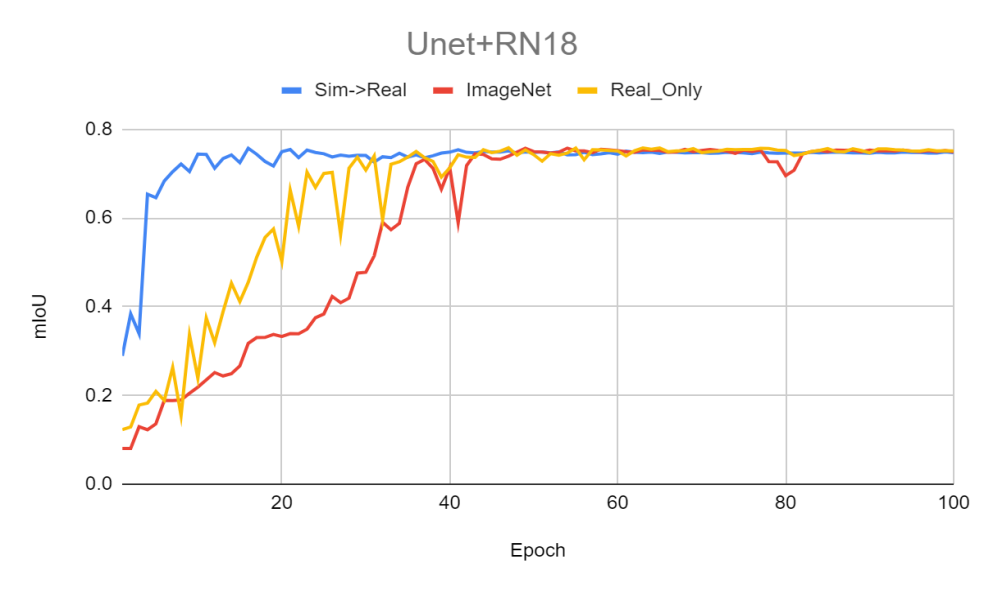
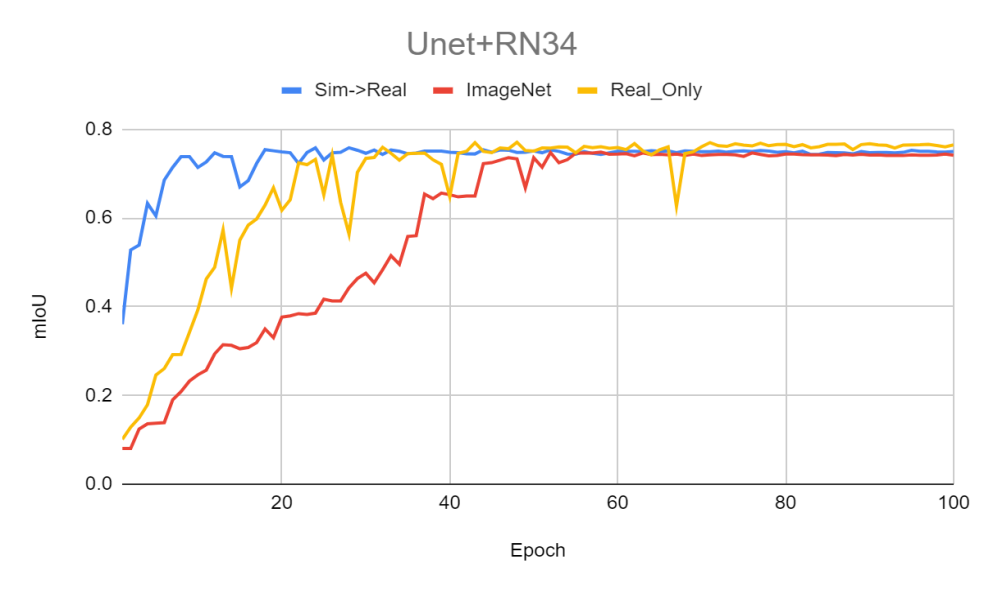
4.4. Depth Camera 좌표 변환 기반 모사 결과
Ray 기반 센서 모사의 한계를 보완하기 위해, Depth Camera의 FOV를 조정한 뒤 얻어낸 Point Cloud 정보를 활용하여 좌표를 변환하는 실험을 병행했습니다.
그 결과 타겟 소나에 가까운 기하학적 형태의 이미지를 성공적으로 추출할 수 있었습니다.
이는 향후 Image-to-Image Translation이나 domain adaptation 방법을 통해 소나 데이터로 활용할 수 있을 것으로 보입니다.

4.5. 결과 분석
본 연구를 통해 도출된 파이프라인과 그 의의는 크게 세 가지로 요약할 수 있습니다.
- 무한한 데이터 증강과 라벨링 비용 제로(Zero-Cost Annotation): 시뮬레이터 환경을 적극 활용하여 수동 Annotation 작업 없이도 완벽하게 라벨링된 고품질의 소나 이미지를 무한히 획득할 수 있는 자동화 파이프라인을 구축했습니다.
- 도메인 특화 사전 학습(Domain-Specific Pre-training)의 입증: 시뮬레이터 기반 가상 소나 이미지로 먼저 가중치를 학습시킨 Pre-trained 모델이, ImageNet과 같은 일반 광학 이미지 기반의 Pre-trained 모델이나 사전 학습이 아예 없는 모델보다 수중 객체 탐지 학습에 훨씬 더 빠르고 효과적임을 데이터로 입증했습니다.
- 타겟 센서에 최적화된 시각적 모사: Depth Camera 좌표 변환 등의 기법을 적용함으로써 본 연구의 실제 타겟 센서인 ARIS Explorer 3000에 기하학적으로 가깝고 정밀하게 모사된 결과물을 얻어냈습니다.
5. 결론
본 연구는 막대한 비용이 드는 수중 탐사 분야에서, 시뮬레이터를 활용해 가상 데이터를 무한히 증강(Augmentation)함으로써 데이터 수집 비용을 획기적으로 낮추고 실제 AI 모델의 탐지 성능을 높일 수 있는 가능성을 입증했습니다.
성능 최적화를 통해 목표했던 기존 연구의 mIoU 값인 0.7481보다 향상된 결과를 달성했으며, 가상 데이터를 활용한 사전 학습(Pre-training) 기법이 기존 방식보다 학습에 더 효과적이라는 점 또한 실험으로 증명했습니다.
하지만 본 연구를 진행하며 극복해야 할 명확한 한계점도 발견했습니다.
시뮬레이터의 Ray 기반 소나 센서나 Depth Camera 좌표 변환으로 생성된 이미지는 기하학적으로는 타겟 센서와 유사한 장면을 보여주지만, 매질의 특성에 따른 반사나 잔향 등 '수중 소나 특유의 물리적 특성'은 완벽히 고려되지 못했습니다.
따라서 향후 연구에서는 이러한 한계를 극복하기 위해, 시뮬레이터 이미지에 CycleGAN과 같은 생성형 AI(Generative AI) 모델을 이용한 도메인 적응(Domain Adaptation) 기법을 적용할 필요가 있습니다.
실제 ARIS Explorer 3000 소나의 질감과 노이즈 패턴을 더 완벽하게 모사하여 비전 AI(Vision AI)의 일반화 성능과 탐지 정확도를 끌어올린다면, 이 프레임워크는 다양한 실제 산업에 폭넓게 응용될 수 있습니다.
시뮬레이터를 통해 무한히 얻어낸 이미지들은 시야 확보가 극도로 제한되는 심해에서의 인명 구조 작업이나, 기뢰 탐지, 잠수함 탐지와 같이 고도의 정밀성이 요구되는 수중 탐지 성능을 획기적으로 높이는 데 활용될 수 있을 것입니다.
나아가, 이렇게 향상된 시각 지능을 바탕으로 수중 로봇의 매니퓰레이터(Manipulator)를 정밀하게 제어함으로써 해양 쓰레기를 자동으로 수거하는 등 실질적인 해양 생태계 정화 임무에도 크게 기여할 수 있을 것입니다.
Reference
- Forward-Looking Sonar Marine Debris Datasets
- Singh, Deepak, and Matias Valdenegro-Toro. "The marine debris dataset for forward-looking sonar semantic segmentation." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
- DAVE
이 프로젝트는 2022년, 학부 3학년 시절 연구라는 것을 처음 시작하며 진행했던 프로젝트입니다.
당시에는 그저 단순한 호기심과 열정만으로 아무것도 모르는 수중 로봇이라는 주제를 선정했기에, 돌이켜보면 정말 셀 수 없이 많은 시행착오를 겪었습니다.
가장 큰 패착은 '기본기'의 부재였습니다.
딥러닝이라는 거대한 분야에 대한 배경지식도 얕았고, 무엇보다 소나 데이터를 다루면서도 정작 그 본질인 '수중음향학(Underwater Acoustics)'에 대해서는 완전히 무지했습니다.
명확한 문제 정의나 탄탄한 선행 연구 조사 없이 그저 아이디어를 내고 실험부터 하면서, "잘 될 것 같은 아이디어인데, 대체 왜 안 되지?"만 되뇌었습니다.
이 때 제대로 된 문제 정의가 연구에서 얼마나 중요한지, 그리고 도메인 지식이 얼마나 중요한지 깨닫게 되었습니다.
시간이 흐른 지금 다시 돌아봐도, 시뮬레이터를 활용해 수중 데이터를 무한히 합성하겠다는 이 초기 아이디어 자체는 여전히 흥미롭고 잠재력이 크다고 생각합니다.
4년 전과 비교해서, AI 분야가 전반적으로 굉장히 많이 발전했고 공개 소나 데이터셋도 좀 더 늘어나서 다시 해본다면 재밌는 결과를 얻을 수 있지 않을까 싶은 생각도 듭니다.
Code
https://github.com/sundongpark/sonar_image_save
GitHub - sundongpark/sonar_image_save
Contribute to sundongpark/sonar_image_save development by creating an account on GitHub.
github.com